

LLVM与OLLVM的代码混淆技术解析
0x00 前言
在开始 OLLVM 之前,先介绍一下 LLVM。
LLVM 是构架编译器(compiler)的框架系统,以 C++ 编写而成,用于优化以任意程序语言编写的程序的编译时间(compile-time)、链接时间(link-time)、运行时间(run-time)以及空闲时间(idle-time),对开发者保持开放,并兼容已有脚本。LLVM 命名最早源自于底层虚拟机(Low Level Virtual Machine)的缩写,可是后来,LLVM 从来没有被用作过虚拟机。
LLVM 架构:
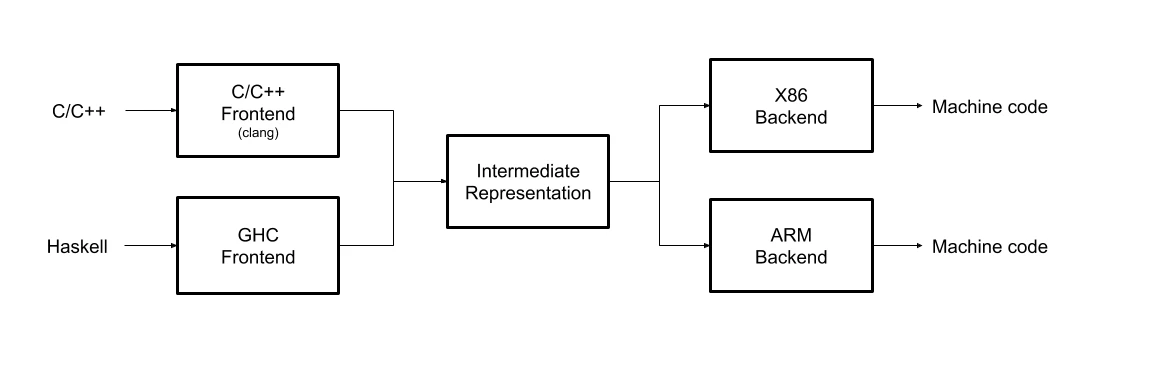
LLVM 是一个优秀的编译器框架,它也采用经典的三段式设计。前端可以使用不同的编译工具对代码文件做词法分析以形成抽象语法树 AST,然后将分析好的代码转换成 LLVM 的中间表示 IR(intermediate representation);中间部分的优化器只对中间表示 IR 操作,通过一系列的 Pass 对 IR 做优化;后端负责将优化好的 IR 解释成对应平台的机器码。LLVM 的优点在于,中间表示 IR 代码编写良好,而且不同的前端语言最终都转换成同一种的 IR。
不同的前端后端使用统一的中间代码 LLVM Intermediate Representation (LLVM IR)
如果需要支持一种新的编程语言,那么只需要实现一个新的前端
如果需要支持一种新的硬件设备,那么只需要实现一个新的后端
优化阶段是一个通用的阶段,它针对的是统一的LLVM IR,不论是支持新的编程语言,还是支持新的硬件设备,都不需要对优化阶段做修改
0x01 OLLVM 介绍
OLLVM(Obfuscator-LLVM)是瑞士西北应用科技大学安全实验室于 2010 年 6 月份发起的一个项目,该项目旨在提供一套开源的针对 LLVM 的代码混淆工具,以增加对逆向工程的难度。
OLLVM 的混淆操作就是在中间表示 IR 层,通过编写 Pass 来混淆 IR,然后后端依据 IR 来生成的目标代码也就被混淆了。得益于 LLVM 的设计,OLLVM 适用 LLVM 支持的所有语言(C, C++, Objective-C, Ada 和 Fortran)和目标平台(x86, x86-64, PowerPC, PowerPC-64, ARM, Thumb, SPARC, Alpha, CellSPU, MIPS, MSP430, SystemZ, 和 XCore)。
0x02 OLLVM 功能
OLLVM 有三大功能,分别是:Instructions Substitution(指令替换)、Bogus Control Flow(虚假控制流)、Control Flow Flattening(控制流平坦化)。
指令替换
随机选择一种功能上等效但更复杂的指令序列替换标准二元运算符;适用范围:加法操作、减法操作、布尔操作(与或非操作)且只能为整数类型。
举个栗子:
加法
a = b - (-c)
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = sub i32 0, %1
%3 = sub nsw i32 %0, %2
r = rand(); a = b + r; a = a + c; a = a - r
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = add i32 %0, 1107414009
%3 = add i32 %2, %1
%4 = sub nsw i32 %3, 1107414009
除此之外,其他的逻辑运算可以写成如下形式:
AND:
a = b & c=>a = (b ^ ~c) & bOR:
a = b | c=>a = (b & c) | (b ^ c)XOR:
a = a ^ b=>a = (~a & b) | (a & ~b)
虚假控制流
虚假控制流混淆主要通过加入包含不透明谓词的条件跳转和不可达的基本块,来干扰 IDA 的控制流分析和 F5 反汇编。
不透明谓词
在混淆时,如果一个表达式的值已知,但是破解者却很难通过表达式本身推断它的值,那么它就是一个不透明表达式。最常见的不透明表达式即不透明谓词。不透明谓词是永真或永假或时真时假的布尔表达式。
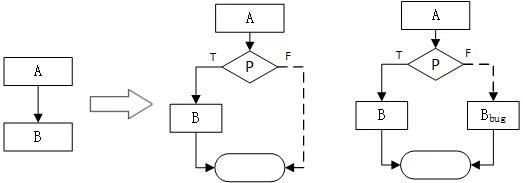
对于顺序执行的基本块,通过构造恒真或恒假的不透明谓词,使程序中多了一条伪分支,这样使控制流的结构更为复杂,也可以构造可为真也可为假的不透明谓词,在程序中添加等价基本块,使程序执行结果无论为真还是为假都能正确执行,这样也可以使控制流复杂化。
恒真或恒假的不透明谓词:
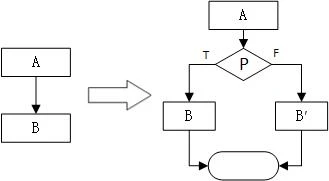
可为真也可为假的不透明谓词:
举个栗子:
int add(int a, int b, double x)
{
if ((int)(pow(x, 2.0) + x) % 2 == 0)
return a + b;
else
return a * b;
}
插入多余控制流
压扁控制流算法是通过重新组织控制流,使静态分析工具无法构建出原有控制流。插入多余控制流算法,通过向程序中插入多余控制流的方法来实现控制流的复杂化。这一算法的主要实现方法是分离程序中的基本块并插入不透明表达式。
比如,在循环条件 \text{P}中加入不透明谓词,使程序看上去必须要在 \text{P}和 \text{P}^\text{T} 都为真的时候才能继续执行。
循环条件中插入不透明谓词:
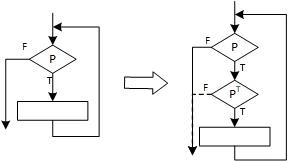
按照结构化的编程规则,用嵌套的判断和循环语句编程,程序的控制流图就是可归约的。这一类程序的控制流相对清晰。如果在程序中加上直接跳转到循环内部的语句,那么这个循环就会多出一个入口。这样生成的控制流图就是不可归约的。
举个栗子:
while(1)
{
y = 20;
x = y + 10;
return x;
}
在循环开始前插入条件判断语句,让其跳转到循环内部,修改后代码如下:
if(PF) goto b;
while(1)
{
x = y + 10;
return x
b : y = 20;
}
控制流平坦化
控制流扁平可以将源代码结构改变,使得程序的逻辑复杂不易被静态分析,增加逆向难度。
举个栗子:
int modexp(int y, int x[], int w, int n)
{
int R, L;
int k = 0;
int s = 1;
while(k < w)
{
if (x[k] == 1)
R = (s * y) % n;
else
R = s;
s = R * R % n;
L = R;
k++;
}
return L;
}
控制流平坦化 - 原代码:
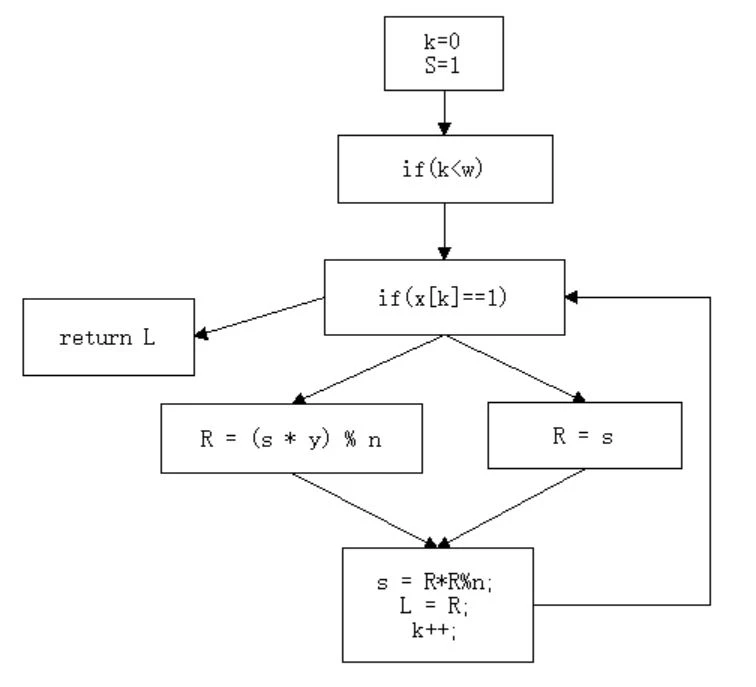
这里我们用 if 来代替 while,这样可以使得逻辑更加清晰。这幅图就是扁平前的效果,可以看到程序基本是从上往下执行的,逻辑线路非常明确。
而当我们对它进行了扁平化处理之后,就变成这样:
int modexp(int y, int x[], int w, int n)
{
int R, L, s, k;
int next = 0;
for(;;)
{
switch(next)
{
case 0: k = 0; s = 1; next = 1; break;
case 1: if(k<w) next = 2; else next = 6; break;
case 2: if(x[k]==1) next = 3; else next = 4; break;
case 3: R=(s * y) % n; next = 5; break;
case 4: R = s; next = 5; break;
case 5: s=R * R % n; L = R; k++; next = 1; break;
case 6: return L;
}
}
}
控制流平坦化 - 处理后代码:
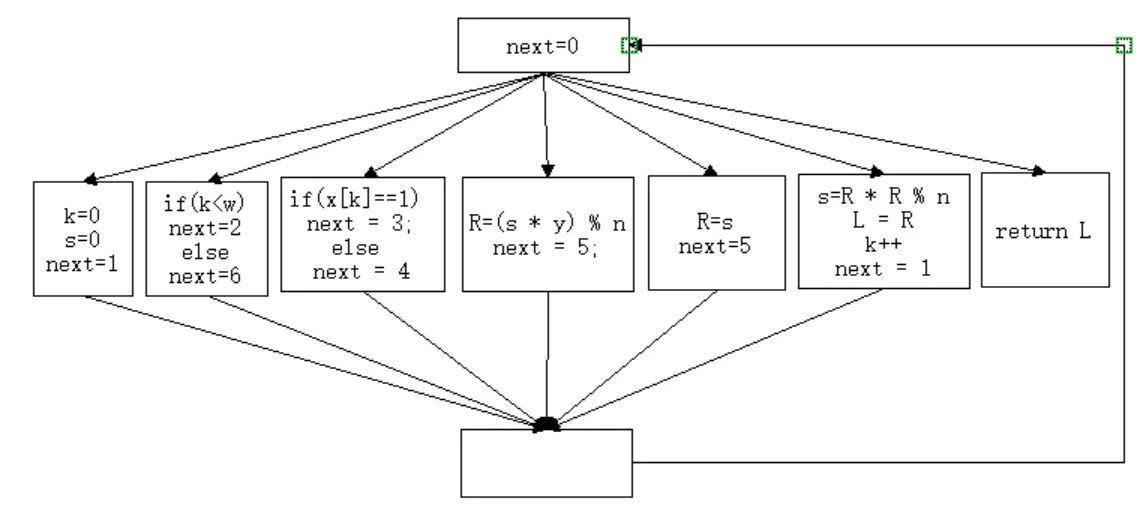
一般扁平算法基本步骤如下:
将函数体拆分为多个基本块,构建控制流图。将这些原本属于不同层级的基本块放到同一层级;
将所有基本块封装到一个
switch选择分支当中;用一个状态变量来表示当前状态,进行逻辑顺序控制(上述代码中的
next变量)。
改变原有结构往往会带来一些副作用,比如局部变量的声明要提前,否则不同分支无法使用同一个变量。
除此之外的副作用还有:
由于声明提前,声明和赋值过程分离,而引用类型需要声明的同时定义;
构造函数和析构函数会因为声明位置而产生副作用;
带来同名变量的问题,即原本不同作用域名称相同的变量变成同作用域名称相同的变量;
try-catch语句可能会遇到的执行顺序问题。
除了要处理这些副作用之外,源代码中本来的 while、do-while、for 循环包括原本的 switch-case 分支统统需要改为 if-goto 的形式。然后再进行 switch-case 的封装。
最终的算法执行顺序为:
标识符重命名(解决变量名冲突)
控制语句展开(全变成
if)变量声明提前
针对基本类型和指针类型按以下步骤执行:
将声明提前
如果原来有初始化行为,则在原来的位置增加赋值语句,用初始化值赋值
如果没有初始化行为则赋值为 0
引用变量需要变为指针变量按上述步骤执行。
针对对象的构造和析构按照以下步骤执行:
在起始处用 auto_ptr 分配一段对象大小的内存
在原来初始化的位置用 placement new 语句对 auto_ptr 的内存进行初始化
原始代码中引用对象的位置改为 auto_ptr 解引用
在隐式析构的位置显示调用析构函数
控制流压扁
但是,在上述的过程中,所有的 next 都是直接写出来的,所以,我们要使用不透明谓词解决该问题。
举个栗子:
int a[] = {1, 2, 4, 12, 16...}
int i = 0;
int next = a[0] - 1;
switch(next)
{
case 0: ...; next = a[i + 1] - a[i]; i++; break;
case 1: ...; next = a[i + 2] / a[i + 1]; i+=2; break;
case 2: ...; return ;
case 3: ...; next = a[i + 1] - a[i]; i--; break;
case 4: ...; next = a[i - 2] * a[i - 1]; break;
}
为了提高难度可以将数组定义为全局变量,在其他地方生成,甚至动态生成,只要保持一定的数学关系即可。
对于 OLLVM 中的基本流程如下:
添加一个随机数种子 blockID
保存所有的基本块
将代码中含有
switch改为if删除第一个基本块,第一个需要特殊处理
识别
main中的if,并且删除跳转指令插入一个
switch指令第一个块跳转到
loopEntry块把所有的 block 保存到
switch语句重新计算
switch变量的值处理不是条件跳转:直接删除 jump 跳转到
loopEnd进行下一轮循环处理条件跳转:对真分支和假分支进行相应处理,真则选择真的 ID
由于处理流程会先将 switch 改为 if-else,再将所有的 if-else 变为 switch,所以多次进行控制流平坦化就会变得越来越复杂
参考资料:
深入浅出让你理解什么是LLVM https://www.jianshu.com/p/1367dad95445
A tutorial on how to write a compiler using LLVM https://tomassetti.me/a-tutorial-on-how-to-write-a-compiler-using-llvm/
android逆向奇技淫巧十:OLLVM原理、常见破解思路和hook代码 https://www.cnblogs.com/theseventhson/p/14861940.html
LLVM第二弹—— OLLVM环境搭建、源码分析及使用 https://blog.csdn.net/weixin_38244174/article/details/82889725
Android APP漏洞之战(14)——Ollvm混淆与反混淆 https://bbs.kanxue.com/thread-274532.htm
代码保护技术:控制流混淆 https://blog.csdn.net/qq_40110132/article/details/84331162
代码混淆之道——控制流扁平与不透明谓词理论篇 https://www.cnblogs.com/ichunqiu/p/7383045.html
Instructions Substitution https://github.com/obfuscator-llvm/obfuscator/wiki/Instructions-Substitution
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝



